This ordinary Tuesday? Two. Two AI slop security reports arrived to #curl. So far.

This ordinary Tuesday? Two. Two AI slop security reports arrived to #curl. So far.
Four years ago we introduced this #curl graph

We got another "critical vulnerability" on #curl reported. I figured you might enjoy it.
"The authentication mechanism in cURL does not properly restrict the number of failed authentication attempts, allowing an attacker to brute-force credentials"
Yawn. Away, away you go.
Sunday surprise!
A friend of mine found an old email from me dated January 17 1997
Attached in this mail was the #httpget 0.2 source code. Previously believed to be lost, now the oldest httpget code I have.
165 lines long. 110 lines code, 30 lines comments, 25 blank lines.
This morning, #curl was 174,854 lines of code, not counting blank lines but comments.
1248 times larger over 28 years.
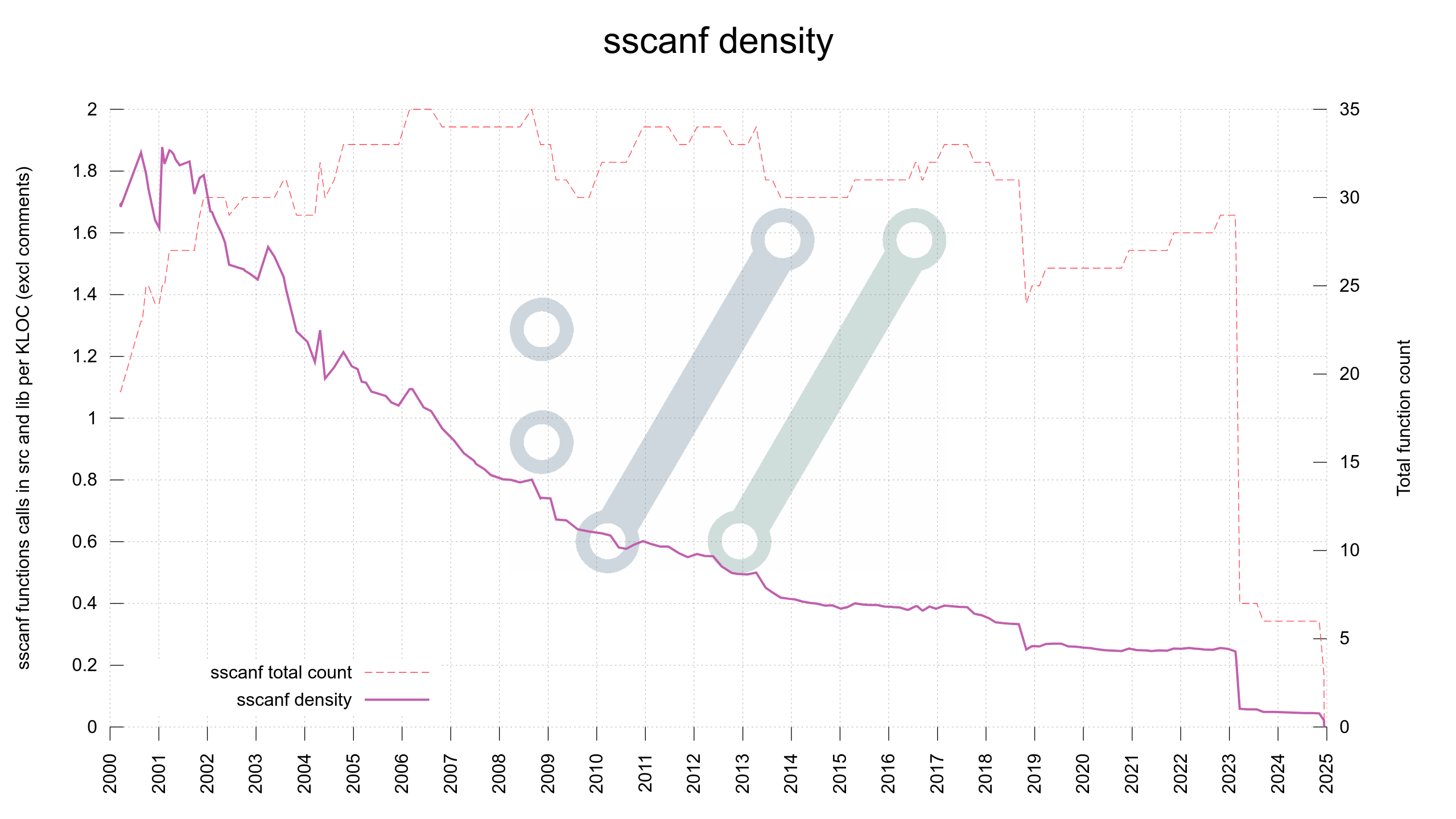
CVSS is dead to us
25 years later, #curl is now at 0 sscanf calls - and we do not allow new ones to get added
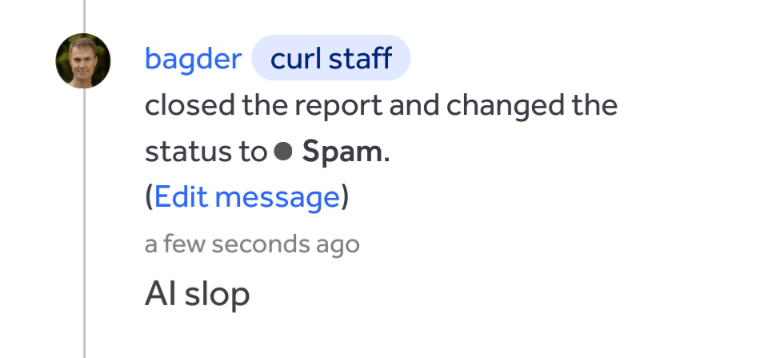
The #curl GitHub AI issue was removed. A screenshot of it is here:
Here's a link to today's AI slop #curl #hackerone report. Freshly disclosed:
Marking them as spam now. #curl #hackerone (AI slop as "security vulnerability reports")
For more than 20 years, I’ve downloaded files using wget because I could never remember curl options.
It turns out that I was not alone.
@samueloph created a simple wrapper around curl called "wcurl". This is brilliant! And, yes, the name is very intuitive. Best of all, it is already in Debian (and on my system) but it should really be part of the official curl distribution (ping @bagder )
https://samueloph.dev/blog/announcing-wcurl-a-curl-wrapper-to-download-files/
")
{kind=link}